Ultimate guide to sorting strings in Java
The minimum every senior developer must know about sorting strings in Java
String manipulation is one of the most fundamental tasks of every developer. We create strings, read them, cut them, join them, pad them, and generally do dozens of different processing activities on them. One of the most common of those is sorting. At first glance, sorting looks like an easy and long-solved problem… if you’re only dealing with the 26 letters of the English alphabet, that is. For almost any real-world application, sorting is filled with gotchas and intricacies. In this ultimate guide to string sorting, I’ll dive deeply and answer questions about sorting strings with numbers, in mixed uppercase and lowercase, with accented letters, etc. Fasten your seatbelts!
Java’s default sorting
Out of the box, Java’s string sorting works similarly to sorting in other programming languages. Each string is treated as a sequence of characters and each character within that string has its corresponding numeric code point. The most well-known character encoding is called Unicode and those code points are defined by the Unicode Consortium. The mapping of characters to code points is available on the Unicode site. The general rule is that numbers come before capital letters, and capital letters come before lowercase letters. As an example, the string Java corresponds to these four code points: U+004A U+0061 U+0076 U+0061 or, if you turn them into decimal values, 74 97 118 97.
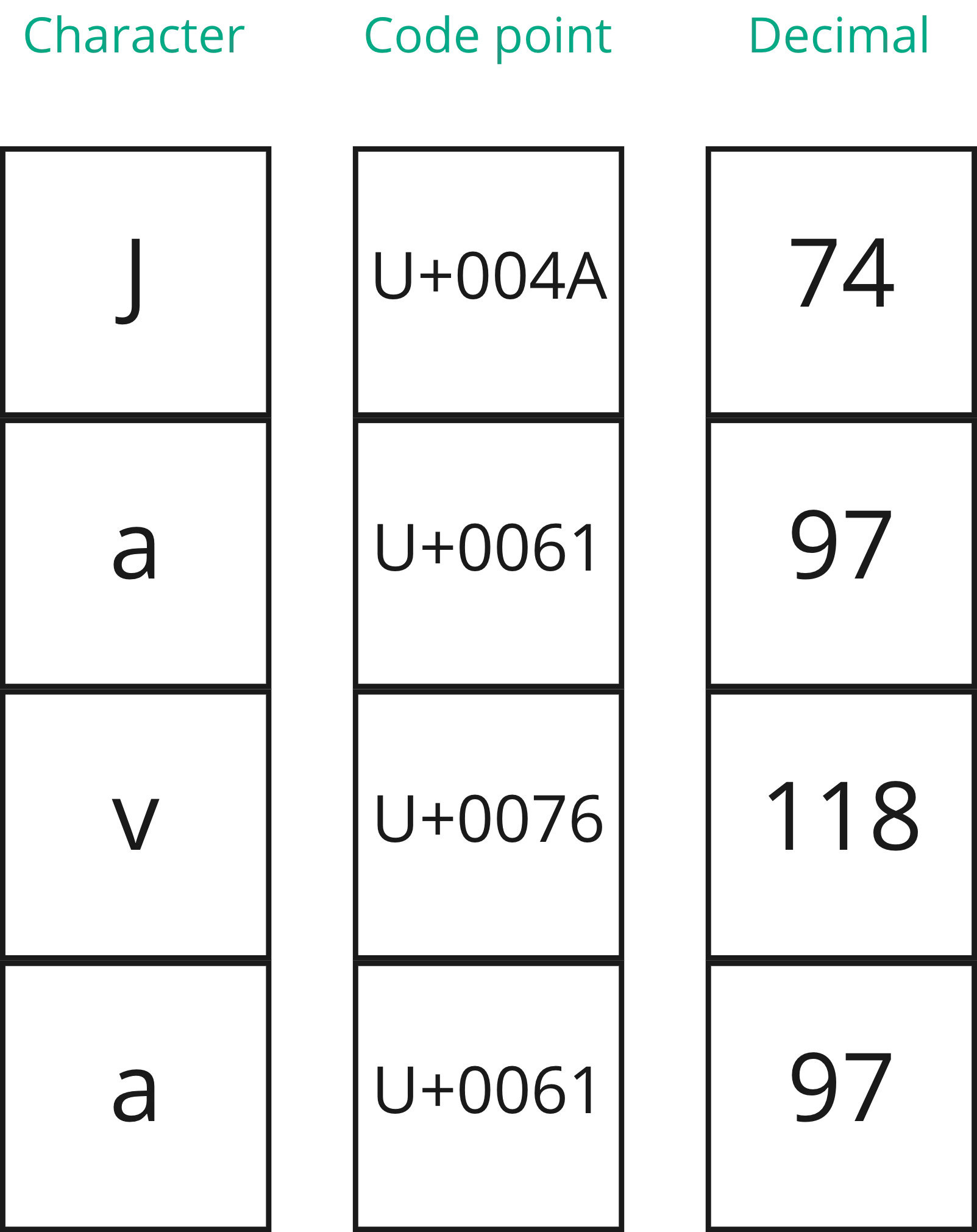
Sorting two or more strings is then simply a process of comparing their characters’ code points, starting from the character at position (index) 0. The first position in which code points differ will determine the order of those 2 strings – a lesser code point means that string comes before the other one.
Let’s see a few commented examples of Java’s default sorting.
List<String> singleLetters = List.of("a", "B", "b", "A");
System.out.println(singleLetters.stream().sorted().collect(Collectors.joining(", ")));
//A, B, a, bCapital letters come before lowercase ones (i.e. they have lower values of code points), so the result is A, B, a, b. No surprises there. And what about numbers?
List<String> lettersAndNumbers = List.of("a", "B", "b", "A", "0", "1", "2");
System.out.println(lettersAndNumbers.stream().sorted().collect(Collectors.joining(", ")));
//0, 1, 2, A, B, a, bNumbers have a lower value of code points, so they come first, i.e., before capital letters. Everything looks good so far, but things start to complicate quickly if we have strings with multi-digit numbers.
List<String> justNumbers = List.of("10", "215", "0", "1", "2", "3");
System.out.println(justNumbers.stream().sorted().collect(Collectors.joining(", ")));
//0, 1, 10, 2, 215, 3While developers might’ve been used to sorting number-like strings like this, our users for sure haven’t! Of course, if we have to deal with numbers only, we can always… well, sort them as numbers. In reality, however, we usually have to deal with a mix of letters and numbers in strings. A typical example might be product names:
List<String> productNames = List.of("Laser10", "Laser215", "Laser0", "Laser1", "Laser2", "Laser3");
System.out.println(productNames.stream().sorted().collect(Collectors.joining(", ")));
//Laser0, Laser1, Laser10, Laser2, Laser215, Laser3Now the problem is obvious. A potential customer visiting a website that sorts products like this would surely not be happy. It would be much better if, in this case, we could have Laser0, Laser1, Laser2, Laser3, Laser10, Laser215. To properly deal with such strings, we need alphanumeric sorting.
Alphanumeric sorting
Alphanumeric sorting handles numbers in strings logically, e.g., 10 would come after all single-digit numbers and 100 would come after all double-digit numbers. I’ve found a production-ready implementation of this algorithm on Dave Koelle’s site, which unfortunately has seemed to be dead for some time now. That’s why I created a GitHub gist with the same code, so please check what the code looks like there.
If we try the same example as before, we’ll see that the numbers are sorted logically:
List<String> productNames = List.of("Laser10", "Laser215", "Laser0", "Laser1", "Laser2", "Laser3");
System.out.println(productNames.stream().sorted(new AlphanumComparator()).collect(Collectors.joining(", ")));
//Laser0, Laser1, Laser2, Laser3, Laser10, Laser215AlphanumComparator doesn’t mess with non-number characters, so the sorting results are the same as with Java’s default sorting:
List<String> lettersAndNumbers = List.of("a", "B", "b", "A", "0", "1", "2");
System.out.println(lettersAndNumbers.stream().sorted().collect(Collectors.joining(", ")));
System.out.println(lettersAndNumbers.stream().sorted(new AlphanumComparator()).collect(Collectors.joining(", ")));
//0, 1, 2, A, B, a, b
//0, 1, 2, A, B, a, bWe’ve solved all our sorting problems, case closed, life is good again, right? Well, not exactly. In the real world, we’re mostly dealing with strings longer than 1 character and with mixed upper- and lower-case, like in the following example:
List<String> suffixedList = Stream.of("A", "AA", "AAA", "a", "aa", "aaa", "b")
.map(s -> s + "Test")
.collect(Collectors.toUnmodifiableList());
System.out.println(String.join(", ", suffixedList));
System.out.println(suffixedList.stream().sorted(new AlphanumComparator()).collect(Collectors.joining(", ")));
//before sort: ATest, AATest, AAATest, aTest, aaTest, aaaTest, bTest
// after sort: AAATest, AATest, ATest, aTest, aaTest, aaaTest, bTestWhat happened here? Why is the order AAA, AA, A for capital letters and a, aa, aaa for lowercase ones? The answer is again in the code points. The decimal code point for A is 65 and for a is 97, so ATest comes before aTest. For T, the decimal code point is 84, so aTest comes before aaTest – the first code points are equal (84 for a), but for the second ones it’s 84 < 97. But if we look at AATest and ATest, it’s vice versa – now the code point for A is < the code point for T, and therefore AATest comes before. If this order looks a bit strange to you, you’re not alone. In dictionaries, the order would be different and would look like this: aaaTest, AAATest, aaTest, AATest, aTest, ATest, bTest. Is there a way out?
Dictionary sorting
In dictionary order (at least in English), uppercase letters sort adjacent to lowercase ones. Maybe the best way to visualize it is by imagining a bunch of books you need to sort by title. Some book titles are printed in uppercase, some in lowercase. People usually don’t want to sort uppercase-titled books and lowercase-titled ones separately! Apart from that, the (primary) rule of default sorting is still valid: a lower code point comes before a higher code point. That’s why in dictionary sort the order is aaaTest, AAATest, aaTest – capital A is adjacent to a, but AAATest comes before aaTest because in the 3rd place we have A and T.
My preferred way of achieving dictionary sorting is Collator. It is an unexpectedly underused class even though it’s been available since Java 1.1! Collator is a Comparator and can be used wherever we would normally use a Comparator (or combine multiple Comparators). Collator performs locale-sensitive string comparison and the rules for one locale can be very different from the rules of another locale, which means that identically looking strings can be sorted differently under different locales! Locale.US must always be available, but otherwise the implementation of your JVM determines the available locales.
If you decide to use Collator, you must use it with the correct locale! Otherwise, you can get weird, unexpected results.
To get a collator for some locale, simply call Collator.getInstance(Locale l) and use it as a comparator:
List<String> suffixedList = new ArrayList<>(Stream.of("aaa", "A", "AA", "AAA", "a", "aa", "b")
.map(s -> s + "Test")
.collect(Collectors.toUnmodifiableList()));
System.out.println(String.join(", ", suffixedList));
System.out.println(suffixedList.stream().sorted(Collator.getInstance(Locale.US)).collect(Collectors.joining(", ")));
//before sort: ATest, AATest, AAATest, aTest, aaTest, aaaTest, bTest
// after sort: aaaTest, AAATest, aaTest, AATest, aTest, ATest, bTestPrimary, secondary, tertiary, identical, OH MY!!!
If you assumed it gets more complicated, you would be right! Collator has a property called strength and it determines which language features (i.e., differences between strings) are considered significant enough to be counted as… well, differences. The exact assignment of strengths to language features is locale dependent! Usually different letters are considered as a primary difference, different accents as secondary, and different case as tertiary. When comparing strings, the difference at the highest level determines the order. By default, the collator is created with tertiary strength.
Since English doesn’t have accents, it’s not the best language to demonstrate this. However for the sake of completeness let’s look at the previous example at different collator strengths:
List<String> suffixedList = new ArrayList<>(Stream.of("aaa", "A", "AA", "AAA", "a", "aa", "b")
.map(s -> s + "Test")
.collect(Collectors.toUnmodifiableList()));
System.out.println("raw = " + String.join(", ", suffixedList));
Collator us = Collator.getInstance(Locale.US);
us.setStrength(Collator.PRIMARY);
System.out.println("pri = " + suffixedList.stream().sorted(us).collect(Collectors.joining(", ")));
us.setStrength(Collator.SECONDARY);
System.out.println("sec = " + suffixedList.stream().sorted(us).collect(Collectors.joining(", ")));
us.setStrength(Collator.TERTIARY);
System.out.println("ter = " + suffixedList.stream().sorted(us).collect(Collectors.joining(", ")));
us.setStrength(Collator.IDENTICAL);
System.out.println("ide = " + suffixedList.stream().sorted(us).collect(Collectors.joining(", ")));
//raw = aaaTest, ATest, AATest, AAATest, aTest, aaTest, bTest
//pri = aaaTest, AAATest, AATest, aaTest, ATest, aTest, bTest
//sec = aaaTest, AAATest, AATest, aaTest, ATest, aTest, bTest
//ter = aaaTest, AAATest, aaTest, AATest, aTest, ATest, bTest
//ide = aaaTest, AAATest, aaTest, AATest, aTest, ATest, bTestPrimary strength doesn’t make a difference between cases and, for it, AATest and aaTest are identical and are sorted like that just because AATest comes first in the original list. Tertiary strength, however, differentiates between cases and always puts lowercase before uppercase, so aaTest comes before AATest.
Finally, let’s see a similar example just for some language that has accents:
Locale sr_RS_Latn = new Locale("sr", "RS", "#Latn");
Collator sr = Collator.getInstance(sr_RS_Latn);
List<String> serbian = Arrays.asList("Ćićo", "Cico", "cico", "ćićo");
System.out.println("raw = " + String.join(", ", serbian));
sr.setStrength(Collator.PRIMARY);
System.out.println("pri = " + serbian.stream().sorted(sr).collect(Collectors.joining(", ")));
sr.setStrength(Collator.SECONDARY);
System.out.println("sec = " + serbian.stream().sorted(sr).collect(Collectors.joining(", ")));
sr.setStrength(Collator.TERTIARY);
System.out.println("ter = " + serbian.stream().sorted(sr).collect(Collectors.joining(", ")));
sr.setStrength(Collator.IDENTICAL);
System.out.println("ide = " + serbian.stream().sorted(sr).collect(Collectors.joining(", ")));
//raw = Ćićo, Cico, cico, ćićo
//pri = Ćićo, Cico, cico, ćićo
//sec = Cico, cico, Ćićo, ćićo
//ter = cico, Cico, ćićo, Ćićo
//ide = cico, Cico, ćićo, ĆićoHere, primary strength again doesn’t care about cases or accents. But secondary strength does, so it puts ć after c. Tertiary strength differentiates cases, so it puts cico before Cico, and continues to sort accents the same way as the secondary strength.
Reversing sort order
All previous examples used ascending sort order. In practice, you sometimes need to sort in reverse order. Luckily, it’s very easy to do.
If you used the default (natural) sort order, simply call Comparator.reverseOrder() and your stream will be reverse sorted:
List<String> lettersAndNumbers = List.of("a", "B", "b", "A", "0", "1", "2");
System.out.println("for = " + lettersAndNumbers.stream().sorted().collect(Collectors.joining(", ")));
System.out.println("rev = " + lettersAndNumbers.stream().sorted(Comparator.reverseOrder()).collect(Collectors.joining(", ")));
//for = 0, 1, 2, A, B, a, b
//rev = b, a, B, A, 2, 1, 0If you used some custom comparator like AlphanumComparator or Collator, just call reversed() method on it:
List<String> productNames = List.of("Laser10", "Laser215", "Laser0", "Laser1", "Laser2", "Laser3");
System.out.println("for = " + productNames.stream().sorted(new AlphanumComparator()).collect(Collectors.joining(", ")));
System.out.println("rev = " + productNames.stream().sorted(new AlphanumComparator().reversed()).collect(Collectors.joining(", ")));
//for = Laser0, Laser1, Laser2, Laser3, Laser10, Laser215
//rev = Laser215, Laser10, Laser3, Laser2, Laser1, Laser0Combining multiple sorting criteria
No matter how powerful our comparator is, sometimes it’s not enough and we must use more than one at the same time. In other words, we must apply multiple sorting criteria. As an example, let’s say we must first order strings by length and then by natural (default) order. For that, we use a chain of comparing and thenComparing methods:
List<String> numbers = List.of("one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten");
System.out.println(numbers.stream().sorted().collect(Collectors.joining(", ")));
Comparator<String> multiple = Comparator.comparingInt(String::length).thenComparing(Comparator.naturalOrder());
System.out.println(numbers.stream().sorted(multiple).collect(Collectors.joining(", ")));
//eight, five, four, nine, one, seven, six, ten, three, two
//one, six, ten, two, five, four, nine, eight, seven, threeThe first line of output is just a normal default (natural) order: eight comes before five, five comes before four, etc. But the second line is interesting – first all the strings of length 3 are written, then of length 4, and finally of length 5. That’s our primary criterion defined by Comparator.comparingInt(String::length). Then, within each of these groups, we apply our secondary criterion, in our case, natural order, defined by thenComparing(Comparator.naturalOrder()). If you need another one, you can easily chain it with more thenComparing calls.
Writing your own comparator
Sometimes we have no other option but to implement our own comparator. You’ve already seen one such comparator here – AlphanumComparator. To implement your own, you must implement the Comparator functional interface and its method public int compare(String o1, String o2). Of course, in Java 8+, you can write a lambda for that. Here is (a useless) one that compares strings by their second character:
Comparator<String> bySecondCharacter = Comparator.comparingInt(o -> o.charAt(1));Dear fellow developer, thank you for reading this ultimate guide to string sorting in Java. Until next time, TheJavaGuy salutes you 👋!